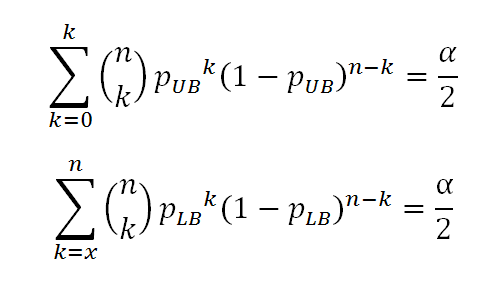Thank you again for such a detailed post about this problem.
I have only one question:
Shouldn’t Part 2 better be posted in Gameplay Feedback?
I think it’d have a higher chance of getting attention by the staff that way.
Thank you again for such a detailed post about this problem.
I have only one question:
Shouldn’t Part 2 better be posted in Gameplay Feedback?
I think it’d have a higher chance of getting attention by the staff that way.
I was pinged over at Reddit to take a look at this, some comments:
[quote=“CookyKim, post:1, topic:320759”]…the true drop rate must be between 0.1627% - 1.022% with 95% confidence.
[/quote]
That is not what your confidence interval (or any confidence interval) means. The population parameter (“the true drop rate”) is in the interval with trivial probability of 0 or 1. The interval, and its confidence level, tells you nothing about the probability of the specific realized interval containing the parameter.
[quote]…Therefore I conclude that the observed drop rate of my wizard must be between 0.002665% - 0.3876% with 95% confidence.[/quote]This makes zero sense - the “observed drop rate” (the sample statistic) is always in your confidence interval, i.e., with probability 1. Again, the confidence level tells you nothing about the probability of the specific sample interval containing the actual population parameter.
Lastly, you’re comparing an SRS with an inverse sample with a stopping rule of 1 success. That’s a bit hinky - it should be obvious the latter creates a biased estimator from the sample (i.e., you will on average over-estimate the “drop rate” using such a scheme). For example, were you to do the same for a fair coin flip, your average estimator for the probability of a given face would be >0.69, instead of the correct 0.5, and the bias gets worse as actual success probability goes down.
This makes the comparison of the initial kills (using SRS) and the final kills (using your inverse sampling scheme) questionable. In addition, even assuming IID, using the estimator of ~0.005 from your initial tests, a train of 190 failures followed by a success within 40-ish trials will happen ~8% of the overall trials - rare, but not ludicrously so.
I’d suggest a better test would be to use a single character, over a large number of trials, and using cluster analysis or fitting the intervals between successes to the Pascal distribution - either will clearly indicate any non-IID behavior.
This is a good start, and with some refinement the above niggling issues can be easily resolved.
Like I said in the disclaimer, I’m not an expert in statistics and the last time I did serious statistics was many years ago. I will gladly modify the statistical tests to make a better conclusion.
However, it would probably be more helpful for you to demonstrate your way of doing the test statistics - the data is there:
Simply criticizing my methodology (which I already admitted up front might not be the best way to do it), and attempting to discredit me outright without offering your evidence or test methodology helps neither me nor the ToS community.
Despite that I’m going to try and reply to some of your critics.
I may not have used the proper statistical terminology here. However, assuming an individual success chance of 0.1627%, with 999 trials, the probability of getting more than 5 successes is less than 2.5%, is that not?
Similarly if the individual success chance is 1.022% is it not true that with 999 trials, that the probability of getting less than 5 (i.e. 4 or less) success is 2.5%?
Then why is it wrong to conclude that 95% of the time I will observe 5 success out of 999 trials if the individual success rate is between 0.1627% and 1.022%? Could I just use an average: 5/999 = 0.055? That doesn’t seem right because I can’t pin point an individual success chance just by using any sample size without a range. And if I were to use a range, what parameters will define the upper and lower limit of that range? Obviously we know the true success chance has to be between 0 - 1, but what kind of information is that? It’s like saying your drop chance is between getting nothing (0) and getting it every time (1, or 100%).
Intuitively we can tell that the actual DPK count for the CSB is 200. That makes 1/200 = 0.5%. My 95% range encompasses this drop rate 0.1627% - 0.5% - 1.022%. So at least it isn’t a completely ridiculous claim.
If this is indeed an incorrect conclusion, then how will you go about solving this question: What’s the likely (range of) individual success chance if given 5 successes out of 999 trials?
Edit 8/14: I have found the answer to my own question in post #20
I’m not entirely sure what this paragraph means (sorry). However all I know is that if the patterned trials were governed by a fixed success rate RNG, that we would observe the same drop rate as the initial 999 trials. Since we observed a different drop rate: 5 in 999; 0 in 950; 5 in 39, it most probably isn’t a fixed success rate RNG.
Any reasonable person who were told these 3 results (5/999, 0/950, 5/39) would intuitively know they don’t share the same drop rate, and if due to chance, it would be an extremely small one. My test was trying to quantify how small this chance was. And if you have a better method to quantify this chance. Then please show us.
It’s 190 failures followed by a success within 15 trials (average 8) for 5 repetitions. i.e 950 trials of failures and 39 trials with 5 successes. I’m pretty sure THAT doesn’t happen 8% of the time due to random chance. Get me 100 people to go to RO and farm something with 0.5% and tell me an average of 8 of them is going to get 5 success in 39 trials? I don’t think so. In fact, using a binomial calculator:
Binomial distribution:
Probability of success in a single trial = 0.005
No. of trials: 39
P(X>=5) = 1.56155980202133E-06
i.e. statistically impossible.
Please do that. I’m not too familiar with cluster analysis or the pascal distribution. Also whether it is 1 character or 2 character is arbitrary - unless the drop rate is tied down per character. I did the 2 character test, just for clarity sake and for people to intuitively understand the implications of a count based drop system.
I realized I did not include the data for the first 999 trials I will list them here:
2nd phase of testing (combining the numbers on both wiz and cleric):
With that I’m pretty sure you have all the information you need to do a test statistics to prove if this drop pattern is due to random chance or not.
I just noticed this topic and looked at my old data I used for the drop tables on TOSBase. Please note that those were from the korean CBT and have been removed a long time ago so they are pretty outdated and I started using user submitted data instead. Those files indeed have a DPK value. There is also a “EPIK” value but I’m not sure if it’s used.
For Pokubo -> Crude Short Bow I have these values:
DPK_Min: 188
DPK_Max: 207
DPK_Expo: 0
I most certainly will not do your work for you.
In any case, I was asked to look at the work and comment if there were issues. There are, so II simply stated the problems in some of your work.
It appears you do not understand confidence intervals, so start with the Wikipedia entry, it has decent lay explanations and discusses the kind of errors you’ve made here. If you make it past that, continue with Neyman’s original work (you know, the guy that brought the whole idea to fruition) where he makes it clear that treating a realized interval as a probabilistic statement about the true parameter is fallacious. For the most rigorous, consult any mathematical statistics text including confidence theory.
As for the rest of the reply, you again use a biased estimator to come up with a probability that has no intrinsic meaning. Not sure how much more clear an explanation of why that’s a biased estimator and why it’s a problem treating it as you do could be made. G-Search inverse sampling, or again consult a text covering sampling and estimation methodologies, it makes little sense to try to give a statistics lesson in a fora post.
Let me be clear - I have no horse in this race, and don’t give a rat’s backside what the “reality” is here with the drop system, I simply gave the courtesy of taking a look when asked, and replying to make you aware of the deficiencies.
Sorry you seem to have taken that as a personal affront - mathematics and critique of same is no place for feelings…
I’m merely responding in the same spirit as you have entered this thread. You have so far provided empty critique with nothing constructive for this thread, except to raise suspicion on the validity of my conclusions to ToS readers. I will be eagerly waiting for your conclusions.
Anyway, you’ve made me dug deeper into this topic - and that made me realized a couple of mistakes in my Confidence Interval (or Confidence Limit, different text use different names). I have corrected my original CI of estimated true drop rate from 0.1627% - 1.022% to 0.1627% - 1.164%; and cleric’s drop rate from 4.297% - 24.22% to 4.297% - 27.43% all with a confidence level of 95%. These corrections did not alter the conclusion.
[quote=“Mathinator, post:19, topic:320759”]
It appears you do not understand confidence intervals, so start with the Wikipedia entry, it has decent lay explanations and discusses the kind of errors you’ve made here.[/quote]
I don’t know what kind of confidence interval you are interpreting here. There’re many kinds of confidence intervals and I have found the name for the confidence interval I was calculating. I understood the concept but never learned the name from my basic stats class in college. Anyway this 95% confidence interval is called the Clopper-Pearson interval, also known as exact method interval. The calculation of which is very complicated and in my original presentation I used a lookup method to find the exact intervals I was looking for (albeit with mistake that I corrected as noted above). However after some digging I found an online calculator that would give you this interval.
And here I quote sigmazone.com’s explanation of this interval:
The deficiencies in the Normal Approximation were addressed by Clopper and Pearson when they developed the Clopper-Pearson method which is commonly referred to as the “Exact Confidence Interval” [3]. Instead of using a Normal Approximation, the Exact CI inverts two single-tailed Binomial test at the desired alpha. Specifically, the Exact CI is range from plb to pub that satisfies the following conditions [2].
While the Normal Approximation method is easy to teach and understand, I would rather deliver a lesson on quantum mechanics than attempt to explain the equations behind the Exact Confidence Interval. While the population proportion falls in the range plb to pub, the calculation of these values is non-trivial and for most requires the use of a computer. You may note that the equations above are based upon the Binomial Cumulative Distribution Function (cdf).
Wikipedia’s description can be found here - Binomial Proportion Confidence interval.
Just because you do not understand the confidence interval I calculated doesn’t mean it has no intrinsic meaning. Perhaps the deficiency here isn’t of mine but your own lack of fundamental understanding of Cumulative Binomial Distributions.
Long story short:
I have provided 95% confidence interval in which the True population p resides for the initial 999 Bernouli Trials; the 950 Wizard trials, and the 39 cleric trials. These 3 intervals do not agree with each other, which means that that it is highly unlikely that these 3 sets of Bernouli trials shared the same population p. i.e. the drop rate system does not have independent trials with a fixed success chance p.
I admit I have only basic lessons in statistics a long time ago, however that doesn’t mean I don’t understand the fundamentals. I’ve not done much in the area of test statistics, so I don’t really know stuff like chi-sq test etc.
What I know is:
As far as logic goes, I don’t see any problems with that conclusion. However, your experience may conclude differently, which will be a good learning opportunity for me at the very least.
I’ve seen somewhere a guy saying he dropped his Dandel Gem at 1300~ kills.
Just killed 1308 dandels (same channel) and it dropped the gem. DPK?
After other people killed 8700 mobs in the channel yeah. Dandel gems are really hard to farm because that map is very large and full of bots so you can’t reliably guess the DPK, in this case it is indistinguishable from RNG.
It was 2 AM when I was farming it, I was alone (1/100) on the channel.
That means nothing unless it was immediately after maintenance.
Our discussion pretty much ends here, with that nonsense.
I assure you, I have a firm understanding of the field. Had you the same, you’d note that the Clopper-Pearson interval has been long out of favor, see e.g. Agresti, & Coull’s “Approximate is better than ‘exact’ for interval estimation of binomial proportions”, you can read it on JSTOR if you have access, might be rough going though… I have a hunch you conflate “exact” with “better”, when in fact the term is directed at the method, not the result, a common mistake by statistical neophytes.
In any case the issue was never with the method used to calculate it, despite it having undesirable coverage probability in most cases, it’s with your incorrect interpretation of what a confidence interval is, fundamentally. Your insistence in ascribing a probabilistic meaning to the realized intervals w/r to the population parameter is flat-out incorrect. It is the kind of thing seen all too often in “statistics for dummies” kind of texts, promulgated by the instructors. It’s at the core of the replication scandal in the social sciences (where the majority of practitioners have the same lack of understanding you appear to possess.)
As I already said, the lay-explanation in the Wikipedia entry under “Meaning and Interpretation” is as simple as it gets, if you can’t grok that, not my problem.
As far as the second gross misunderstanding on your part, if you’ve not even bothered to understand why you are using a biased estimator with your stop-on-success sampling for the continuations, again, not my problem, readers who understand the issue, or take the time to understand it, will see the fallacy.
Your conclusion may well be correct, it’s your methodology and apparently poor understanding of statistics that’s troubling and raises questions about the validity.
As I’ve repeatedly said, I don’t care what the reality is in the result, I get pinged every few weeks by gamers that know of me from Reddit with requests to check such things out.
When I see good math, +! there. When I see problems, I try to make the poster aware. Some use it to fix/learn/understand. Some have temper-tantrums and resort to assumptions of my expertise and insults.
For the former, I’ll help them to understand any way I can.
I will have no truck with the latter.
This is very interesting, could you tell me the value for Battle Bracelet from Galok?
Is it still possible to find these values somewhere online?
I would like to take a look at it.
I wouldn’t worry about it too much, CookyKim. I appreciate the time and effort you’ve put into your data (as well as the time you’ve invested in your posts and your willingness to delve into statistics). I believe that the readers can draw their own conclusions from the data you’ve gathered.
I have no doubt that your conclusion is correct.
Mathinator is likely professionally involved with statistics and he probably also does this as a hobby in his spare time. Based on his knowledge and confidence of the subject, I’d estimate that he is likely aged somewhere in the late forties or even upper fifties. The information contained in his post is definitely not a mishmash of copypasta found around the internet; it seems to be written with knowledge based on direct personal experiences.
That is what he tries to portray, but that still doesn’t change the fact that he has so far came into this thread and repeatedly calling “nonsense” everywhere, meanwhile providing no actual suggestion for improvement. This is what bugs me. You can be an expert but that doesn’t give you the right to behave like a jerk.
He constantly insist that I do not understand what a 95% confidence level means. Yet he has not helped me or the readers understand its actual meaning besides linking to a Wikipedia article. Look if Wikipedia was actually effective in dispelling such misunderstandings, then the misunderstanding would not have occurred in the first place. I have read the wikipedia article among other sites on the web. The information is conflicting and doesn’t always pertain to the topic at hand.
Next, what is this guy’s credentials? Does he truly have credibility? I do not know this internet “expert wanna be”. He has so far offered no link to his reddit persona. He has not demonstrated superior statistical knowledge, besides throwing jargons everywhere, and saying everyone else is wrong. In fact only probability he calculated:
Was flat out wrong. I still do not know how he got that 8% but it is still guaranteed to be wrong because he did not understand the data. It was not 190 failures with a success in ~40 trials. In addtion what kind of expert makes crappy assertions like that? With no actual math to back up his claim?
Finally, he repeatedly insist that something can be done to improve this thread but does not actually want to do anything:
If any of you actually learned something from his posts, or understands the direction he wants me to take to improve the methodology, then please clarify it for me.
So we have an internet self proclaimed expert that goes about different threads boosting his ego, and pisses on people who (naturally) suspect his expertise? Who gave him the right and credentials to go about trashing other people’s thread?
This must be the most ridiculous expert I’ve (not) met in my life. All the experts that I’ve seen are humble and helpful, but this one is arrogant and abrasive.
With that I am going to head over to our local university and ask for help from a math professor that I know. It will take a longer time to get answers but at least it won’t be something ridiculous like this @Mathinator guy.
Edit:
From wikipedia:
The Clopper-Pearson interval is an early and very common method for calculating binomial confidence intervals.[6] The Clopper-Pearson interval is an exact interval since it is based directly on the binomial distribution rather than any approximation to the binomial distribution. This interval never has less than the nominal coverage for any population proportion, but that means that it is usually conservative. For example, the true coverage rate of a 95% Clopper-Pearson interval may be well above 95%, depending on n and θ. Thus the interval may be wider than it needs to be to achieve 95% confidence. In contrast, it is worth noting that other confidence bound may be narrower than their nominal confidence width, i.e., the Normal Approximation (or “Standard”) Interval, Wilson Interval,[3] Agresti-Coull Interval,[8] etc., with a nominal coverage of 95% may in fact cover less than 95%.[2]
So he goes about dissing a commonly used interval - saying it’s out of favor but not actually explaining why it is not appropriate to use in this scenario. Nor has he pointed the correct way to do this. All he claims is “oh this is so outdated, you’re a noob”. Ok, so helpful.
Agresti-Couli interval (adjusted wald)
Interval for 999 trials:
0.1777% - 1.203% (Clopper-Pearson: 0.1627% - 1.164%)
Interval for Wizard:
-0.0831% - 0.4859% (Clopper-Pearson: 0 - 0.3876%)
Interval for Cleric:
5.134% - 27.17% (Clopper-Pearson: 4.297% - 27.30%)
I think I’m getting seriously trolled here. Just putting “Math” in his name and drawing random jargon and he thinks he’s an expert.
From wikipedia:
the confidence interval for the true proportion innate in that coin is a range of possible proportions which may contain the true proportion. A 95% confidence interval for the proportion, for instance, will contain the true proportion 95% of the times that the procedure for constructing the confidence interval is employed. Note that this does not mean that a calculated 95% confidence interval will contain the true proportion with 95% probability. Instead, one should interpret it as follows: the process of drawing a random sample and calculating an accompanying 95% confidence interval will generate a confidence interval that contains the true proportion in 95% of all cases. The odds that any fairly drawn sample from all cases will be inside the confidence range is 95% likely, so there is a 5% risk that a fairly drawn sample will not be inside a 95% confidence interval.
So tell me how have I misinterpreted the actual meaning of confidence interval? have I ascribed probabilistic meaning to the interval? If so quote me on it.
According to the Wikipedia’s:
The process of drawing a random sample and calculating an accompanying 95% CI…
Will generate a confidence interval that contains the true proportion 95% of all cases
I have generated confidence intervals that contains the true proportion (100% probability) (95% of the cases will be correct), and I have demonstrated that the proportions of the 3 tests did not agree, and concluding that the drop system is not a simple RNG. Exactly the same logic I’ve stated previously:
Whereas your suggestion was this:
The confidence interval means that the true population proportion, p, is within that interval. This statement is true 95% of the time. I have not said anything about the probability of the true population proportion, p, being in or outside of this interval in the OP.
Except that this confidence interval isn’t an estimator, and that I have assigned no probability in the original post at all. The more I learn about this topic the more BS your posts seem to be.
I’m beginning to think that @Mathinator isn’t a real statistics expert, but a forum dweller that only knows some key aspects of statistics and the common mistakes that are made within this field. So all he can do is find flags but is unable to actually derive any original work or ideas. You know, like an error checking machine - only able to find errors, but unable to compose or understand the original work.
I just want a running shot gem but its impossible on Klaipeda b/c the large rmt guilds will just monitor each channel to see which is being farmed, they calculate that 300 are bring killed an hour, and they estimate the day the dpk window will open and on that day they send 4 of their guildess out to dibo each spawn and they usually have 2 bots running inbetween each half of the spawns aswell. They wont touch a single dbscap archer until someone else kills 8-9k, really fkng broken, I would love this dpk to be speculation but if its all BS then why does this happen EVERY maintenance/week, that’s not a coincidence.
What has this thread become. I believe in DPK since it helps me get items. And I believe you too, Cookykim.
This system is indeed broken and easily exploited. Which is why I spent my entire weekend on this project - and now maybe even more time to validate it. I also really hope that hkkim will look into this issue, because it is downright frustrating to players who want to farm rares without being kicked in the rear.
@greyhiem
Thanks for your support, but I will get to the bottom of this by having a local professor look at it.
It’s pretty clear that the tests show that the drops are not independent events between the characters. The drops are either universal with a person’s account or from a global counter.
Since other tests were done between two people with different accounts, it’s pretty clear that a global counter is being used to determine when certain items dropped.
All the jargon in this topic doesn’t really matter. This test, as well as many others in the other DPK topic, basically confirms the existence DPK ^o.o^
I fully agree with this. It is quite rude to barge into this thread from out of nowhere to question/call you out on your methods. If someone on Reddit told him to check this out, he simply could have checked it out and messaged the other person back.
Additionally, it is also rude on the front that he is picking apart your post without offering any specifics on how it could be improved. If a person is going to pop into a thread and say anything, they should at least be fully committed to provide exact information on what needs to be changed. This is mainly why I said, “I wouldn’t worry about it” in my earlier post. And, I have no real idea what his credentials are, I was going on intuition when I was judging his character.
I am still working on this question & I am currently brushing up on sampling techniques. What I learned alerted my BS detector:
@Mathinator claims that I’m comparing Simple Random Samples (SRS). My sampling technique of the wizard (sample set B) and cleric (sample set C), 190 followed by ~8 trials until 1 success, is so painfully obvious not SRS. It is a non random sampling with a specific pattern, as samples obtained in all sample sets do not have the same chance of being selected. In fact, set B is dependent on the last drop, and set C is dependent on 190 trials after the last drop. Furthermore, the samples are collected in categories, which is not what SRS does. Finally, this sampling is closest described as consecutive sampling.
This self proclaimed expert doesn’t even seem to understand the thing he is saying (or the experiment).
This question turned out to be a lot harder than I imagined. Although the conclusion is fairly obvious (DPK), I have yet to find a 3rd party to validate my mathematical proof.
The math professor I sought help will not be back until next week. So answer will come much later.